参数学习¶
上一节我们介绍了人工神经网络如何脱胎于生物实体, 成为一个纯粹的数学模型。 这一节我们会看到这个数学模型又是如何从一个理论模型,变为工程上可实际运用的工具。
这一节所考虑的问题是, 在神经网络结构确定之后,如何确定其中的参数, 即上一节中针对单个神经元的 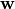 以及
以及 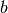 。 为了描述的简洁, 在本节中使用 表示所有需要确定的参数。
。 为了描述的简洁, 在本节中使用 表示所有需要确定的参数。
模型的评价¶
首先我们要讨论如何评价模型参数的好坏, 否则讨论“如何选择好的参数”这个问题就是没有意义的。 这里介绍的是机器学习领域的一般方法。
一个好的神经网络, 对于给定的输入, 能够得到设计者期望的输出。 设输入为 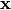 , 输出为
, 输出为 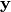 , 我们期望的输出为
, 我们期望的输出为 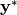 ,可定义实际输出与期望输出的差别作为评价神经网络好坏的指标。 例如可以将两个向量的距离的平方定义为这个差别
,可定义实际输出与期望输出的差别作为评价神经网络好坏的指标。 例如可以将两个向量的距离的平方定义为这个差别
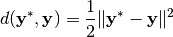
只考察单个样本还不够充分,通常需要考察一个样本的集合,例如有 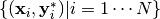 , 定义损失函数为:
, 定义损失函数为:
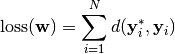
这样的用于评价参数好坏的样本集在机器学习中称为 测试集 。
有监督学习¶
既然损失函数可以用来评价模型的好坏,那么让损失函数的值最小的那组参数就应该是最好的参数:
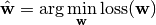
在数学上, 这是一个无约束优化问题, 即调整一组变量使得某个表达式最小(或最大),而对所调整的变量的取值没有限制。
但这里还有个问题, 我们是否可以用测试集上的损失函数来调整参数呢? 答案是否定的, 这会产生严重的过拟合, 即由于参数的学习是依赖于某个给定的样本及标准输出的集合, 那么学习得到的模型就很有可能在这一集合上的损失很低, 但在之外的集合上的损失就会偏高。 那么如果用训练所用集合来评价模型, 分数就会偏高。 还有一个形象的比方是, 考试是用来检验学生对知识的掌握, 学生需要在考试之外也能运用知识。 如果学生在学习时过分针对考试(甚至是知道考试的题目), 那么可以想象这种应试的学习并不能保证学生在考试之外能够真正运用知识。
以上讨论了一大堆, 解决方法其实并不复杂,即使用两个集合,一个是测试集, 一个是训练集, 参数的学习只针对训练集, 找到使训练集损失尽量小的参数, 然后在测试集上测试该组参数面对训练集之外的样本的表现。
梯度下降法¶
解决以上的无约束优化问题, 就成了纯粹的应用数学问题。 梯度下降法是解决这一类问题的基本方法, 也被普遍用于神经网络参数的优化。
梯度下降法是一种迭代的方法。 首先任意选取一组参数, 然后一次次地对这组参数进行微小的调整, 不断使得新的参数的损失函数更小。
这个方法可以这样形象地理解, 不妨设需要优化的参数只有两个, 则参数空间是一个二维的平面。 任意一组参数对应于一个损失函数值, 这构成第三维。 这个三维的空间形成一个曲面, 如同高低不平的地形图, 经纬度表示参数, 高度表示损失函数的值。 那么优化问题就是找到高度最低的经纬度。 梯度下降法的思路是, 首先任意选择一个地点, 然后在当前点找到坡度最陡的方向(例如一个坡面南低北高, 则南北方向坡度大,东西方向坡度小), 沿着该方向向下坡方向迈出一小步, 作为新的地点进行下次迭代。 这样不断地进行迈步, 有可以走到一个海拔较低的地方。
所谓的坡度在数学上就是微积分中的梯度, 梯度下降算法的形式化描述是:
梯度下降算法
- 初始化参数
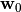 、
、 
- 步数
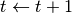
- 计算梯度
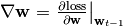
- 更新参数
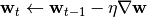
- 如果收敛,结束并输出
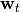 ,否则转到步骤2
,否则转到步骤2
这里主要的计算是第3步,计算梯度。这要求损失函数对于参数可导。
梯度下降法是一个可以用来处理任何非约束优化问题的方法, 但它却不能彻底解决该问题。 它最大的不足是无法保证最终得到全局最优的结果, 即最终的结果通常并不能保证使损失函数最小, 而只能保证在最终结果附近, 没有更好的结果。 因为梯度下降算法在更新参数的过程中, 只利用了参数附近的梯度, 对于整个参数空间的趋势, 它是没有考虑的。
此外, 如果真正尝试在计算机上实现梯度下降算法, 会发现这个已经有理论缺陷的算法在实际使用中, 有更多的问题限制了它的效果。 例如, 步长 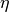 的确定, 如果太小, 算法需要很长时间收敛, 如果太大, 又无法稳定到参数空间中的某一点。不同的设计会影响算法速度以及最终结果的好坏。 但是到目前并没有理论上的好办法解决, 因此步长的确定就从一个科学问题变为了工程问题。 一种方法是让步长随着时间
的确定, 如果太小, 算法需要很长时间收敛, 如果太大, 又无法稳定到参数空间中的某一点。不同的设计会影响算法速度以及最终结果的好坏。 但是到目前并没有理论上的好办法解决, 因此步长的确定就从一个科学问题变为了工程问题。 一种方法是让步长随着时间 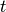 的推移而变小, 即在初期大步走, 到后期小步挪。
的推移而变小, 即在初期大步走, 到后期小步挪。
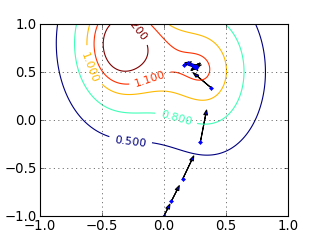
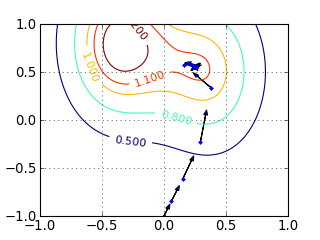
下面这个例子展示了梯度下降算法可能犯的错误。
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
()
优化的目标函数是
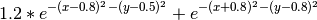
步长是 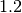 。 迭代从点
。 迭代从点 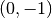 开始, 箭头指示的是梯度下降的方向。
开始, 箭头指示的是梯度下降的方向。
在以上的图中可以看到:
- 由于步长在开始时过小,图中开始时移动比较慢
- 更新比较盲目,没有全局的信息,往往是曲线的
- 后期步长过大,移动过快,在局部最优点周围震荡
- 最终不能收敛到全局最优点